

(2022/7/27 追記) 記事公開から1年経ちましたが、この記事のアクセス数が未だに多いです。みなさん苦労されているのですね。
---
S3に保存したPDFファイルをダウンロードするAPIを、Lambdaで作りました。テキスト表示までは簡単にできたのですが、PDFなどのファイルダウンロードとなると結構設定の変更が必要だったりしてハマりポイントがたくさんあったので、備忘録として残しておきます。お役に立てれば嬉しいです。
AWSのアカウントをまだ作っていない人はこちらから作成しましょう。
やりたかったこと
単純にS3のPDFをダウンロードさせるだけならばS3とAPI Gatewayでできますが、APIのパラメータで取得したテキストを基に、LambdaでPDF編集をして返したかったので、S3, Lambda, API Gateway, Cloud Frontを使いました。
Lambda すらも使うのが初めてだったのですが、Lambdaのチュートリアル自体は簡単でも、PDFをダウンロードすることにこれほど苦労するとは思いませんでした。
ハマりポイント
先に結論として、下記5つのハマりポイントを書いておきます。詳しくは後述する開発手順を見てください。
1. Lambda で Python モジュールを使いたいときはAWSのLinuxでpipする。
Mac上でPython のモジュールを作ってLambdaで実行できるようにしていましたが、何度やってもLambda上でimportエラーになりました。EC2 で Amazon Linux を作ってそこでpipしたPythonモジュールであればすんなり通りました。
2. Lambda で API Gateway にPDFを送信するために base64 で変換する。
Lambda で return するときに、PDFファイルをそのまま body に入れてもエラーとなってしまいます。API Gateway で Lambda の結果を返すには、PDF に限らずすべて base64 でエンコードしてやる必要がありました。
3. API Gateway でバイナリデータ(PDF等のファイル)を取得できるように設定する。
デフォルトの状態では、バイナリデータを返すようにはAPI Gateway はできていません。設定から指定をしてやる必要があります。
4. ブラウザでPDFを表示するためには Cloud Front を使う必要がある
ブラウザでURLを叩けば目的のPDFが表示されてほしいですよね。HTTP Header というもので Accept:application/pdf を指定する必要があるのですが、API Gateway だけだとその指定ができません。なんでやねんとツッコミたくなりますが、ブラウザでPDFを表示させるために、Cloud Front というものを経由してAPI Gatewayを使う必要があります。
5. Cloud Flont の設定で PDF を表示できるようにする。
単純に Cloud Flont を使えば万事解決なのね、と思ったらここにも罠があります。色々な記事でみなさん苦労されているのですが、設定の仕方によってはAccept:application/pdf が API Gateway に送られなかったです。
開発手順
ということで、Lambda でPDFがダウンロードできるようになるまでの開発手順を順に説明していきたいと思います。
S3にPDFファイルを保存
APIで取得したい元ファイルとなるPDFをS3に保存します。
- S3のサービスを表示させます。「バケットを作成」から新規作成します。今回は特にセキュリティが必要なファイルは使いませんので、「パブリックアクセスをすべてブロック」のチェックを外しておきます。セキュリティが必要な方は適宜設定してください。
- バケットが作成できたら、PDFファイルをアップロードしておきましょう。
Lambda の作成
- Lambda にアクセスして右上の「関数の作成」から新規作成していきます。
- 関数名はAPIの名前になります。ランタイムはPython3.7を選びました。
- 「トリガーを追加」から「API Gateway」を選びましょう。REST API で問題ないです。HTTP API との違いはこちら。セキュリティは「オープン」にします。セキュリティが必要な方は設定してください。バイナリメディアタイプの指定を "application/pdf" と入力する必要があります。これを入れないと pdf がブラウザで表示できなくなります。他項目はデフォルトのままとしました。

- この状態で、一度APIが動くかテストしてみましょう。オレンジボタンの「Test」を押します。イベント名を入力して「作成」を押してみましょう。もう一度「Test」を押します。

下記の画面で statusCode 200になっていたら成功です。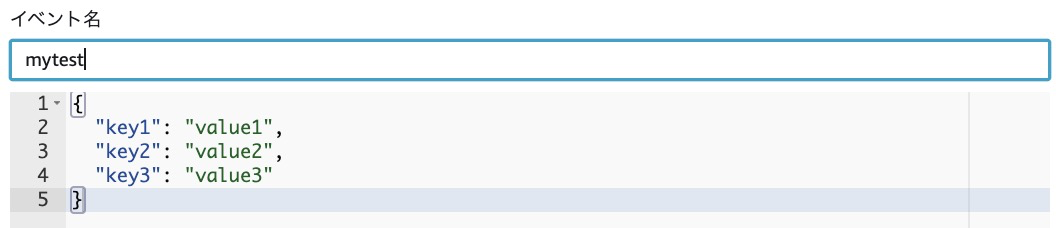
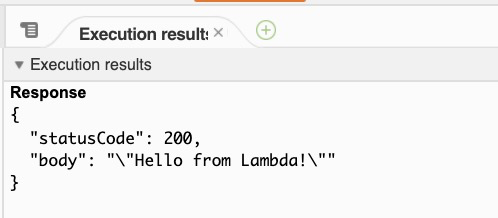
- では、トップページの「API Gateway」のアイコンを押して、「詳細」をクリックすると出てくる「APIエンドポイント」のリンクを選択してみてください。ブラウザで別のタブが開いて"Hello from Lambda!" が表示されるはずです。友だちのスマホで同じURLにアクセスしても結果は同じです。これがAPIを叩いた結果になります。
Lambda の関数の詳しい使い方は、こちらのブログが参考になると思います。以降、進めるたびに「Test」を押してみてください。最後まで行かないとエラーがなくなりませんが、どんなエラーが出ているかが見えると思います。 - 次に、実行ファイルを作ります。例えば、make_pdf_function.py のようなファイルを作ります。その後、忘れずに「Deploy」を押しましょう。Pythonファイルを編集したら、都度「Deploy」を押してコードを反映させる必要があります。なお、ソースコードは、こちらを参考にしてください。
ハマりポイント2ですが、PDFファイルはbase64でエンコードしてやる必要があります。ソースコードの通りです。lambda pdf base 64 などでググると詳細がわかります。 -
このままだと import のモジュールが無いためにエラーとなります。そこで、Python の外部モジュールという形でLambdaに追加をしてやる必要があります。こちらのブログが参考になるかと思います。ハマりポイント1ですが、EC2でAmazon Linux を作ってその中で外部モジュールを作ってください。Lambda はAmazon Linux なので、MacやWindowsで外部モジュールを作っても動きません。外部モジュールは、レイヤーから追加しましょう。
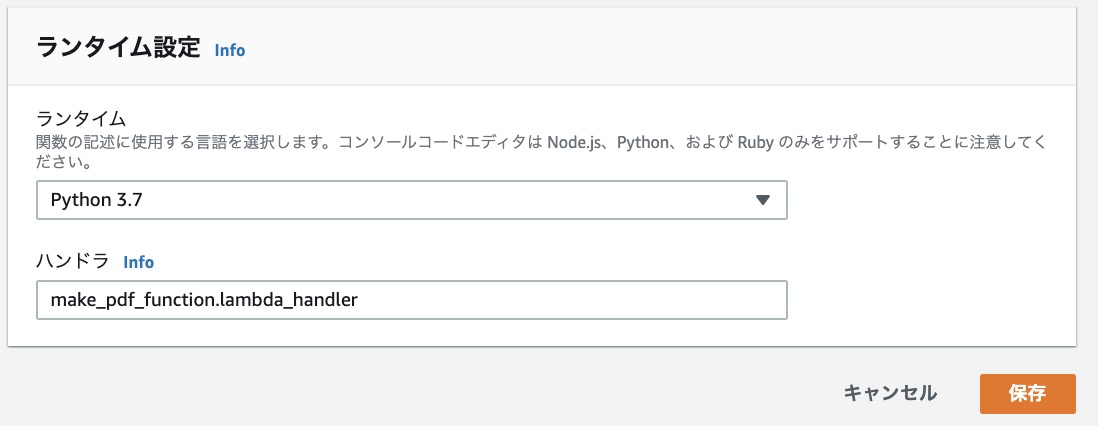
- ランタイム設定の「編集」を押して、ハンドラの設定をします。ハンドラは、APIのURLにアクセスされたときに動く関数の指定です。"pythonファイル名.関数名" で指定することになります。さきほど作成したファイルを指定しましょう。
-
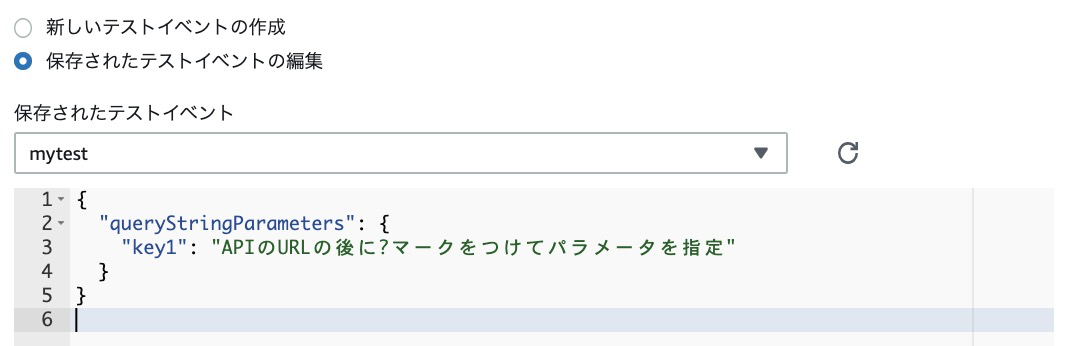
テストのコードを編集しておきましょう。make_pdf_function.py の中でkey1を指定しています。APIでアクセスするときに、「https://hogehoge.com/hoge?key1=aaa」のような形で、?マークの後にパラメータとして文字列を書き、Lambdaの処理にその文字列を渡すことができます。これをJSONで指定しようとすると、"queryStringParameters" を記述することになります。コードはこちらを参照してください。
- S3にアクセスできるように権限設定をしましょう。この状態では、LambdaはS3へのアクセス権がないために、エラーを吐きます。「設定」→「アクセス権限」→「実行ロール」のロール名をクリックしてください。IAM画面に移るので、「ポリシーをアタッチします」を選択し、「AmazonS3ReadOnlyAccess」にチェックを入れて「ポリシーのアタッチ」をします。書き込みも必要であれば FullAccess などにしてください。
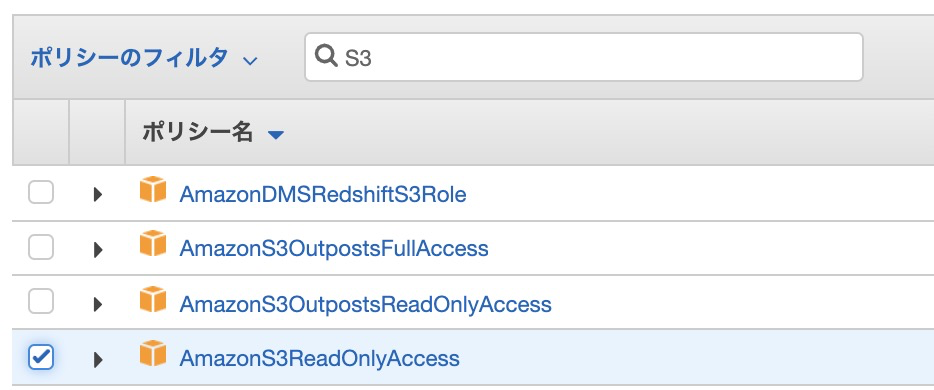
-
では、改めて「Test」を押してみましょう。問題がなければ、S3に保存されたPDFのbase64でエンコードされた文字列が body に入って表示されるはずです。

Lambda の設定は以上です。
API Gateway の準備
- API Gateway のアイコンを押した後に、トリガーに表示されているAPI Gateway のリンクをクリックしましょう。(▶詳細の中のリンクではないです。▶詳細の上に表示されているリンク 〇〇-API のリンクです。)下記のような画面が出るはずです。
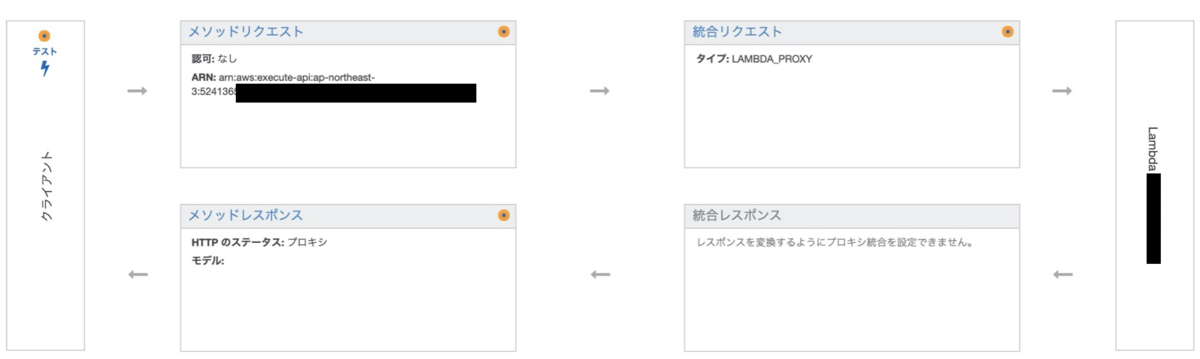
- 左上:メソッドリクエスト
パラメータに指定するキーを入力します。

-
右上:統合リクエスト
そのままで良いです。記事によっては、PDFダウンロードのために「Lambda プロキシ統合の使用」のチェックを外すように記載しているサイトもありますが、当方ではそのままで行けました。逆にチェックを外すと設定がややこしくなります。

- 左下:メソッドレスポンス
200の左の▶を押します。
コンテンツタイプを「application/pdf」、モデルを「Empty」にしておきます。
- 左のタブから「設定」を選びます。
バイナリメディアタイプに、「application/pdf」が入っているか確認してください。変更後は、右下の「変更の保存」を忘れずに押しましょう。
ハマりポイント3ですが、API Gateway 作成時にバイナリメディアタイプの入力をしていないと、ここが空欄になっているはずです。これがないと、APIアクセスされたときにPDFファイルだと認識させることができません。
- では、試しに「テスト」を押してみましょう。メソッドはGETS、key1=aaa などとしてやれば、ステータス200が返ってくるはずです。
"message": "Internal server error" などが表示されていれば、なにかの設定がおかしいです。Lambdaではうまく行っているのに、API Gateway でエラーが出ていれば、API Gateway の設定ミスの可能性が大きいでしょう。key1 の指定がない場合にも、"message": "Internal server error" と表示されます。
API Gateway の設定は以上です。
一旦、実行確認
ここまでくれば実行の確認をしてみましょう。
- Lambdaの画面に戻って、API Gateway の詳細にある、APIエンドポイントのリンクを押してください。たぶん、 {"message": "Internal server error"} が出ます。
- URLの最後に、『?key1=aaa』をつけてみてください。{"message": "Internal server error"} は出なくなったと思います。代わりに、Chorme の場合は下記画面が出ていませんか?
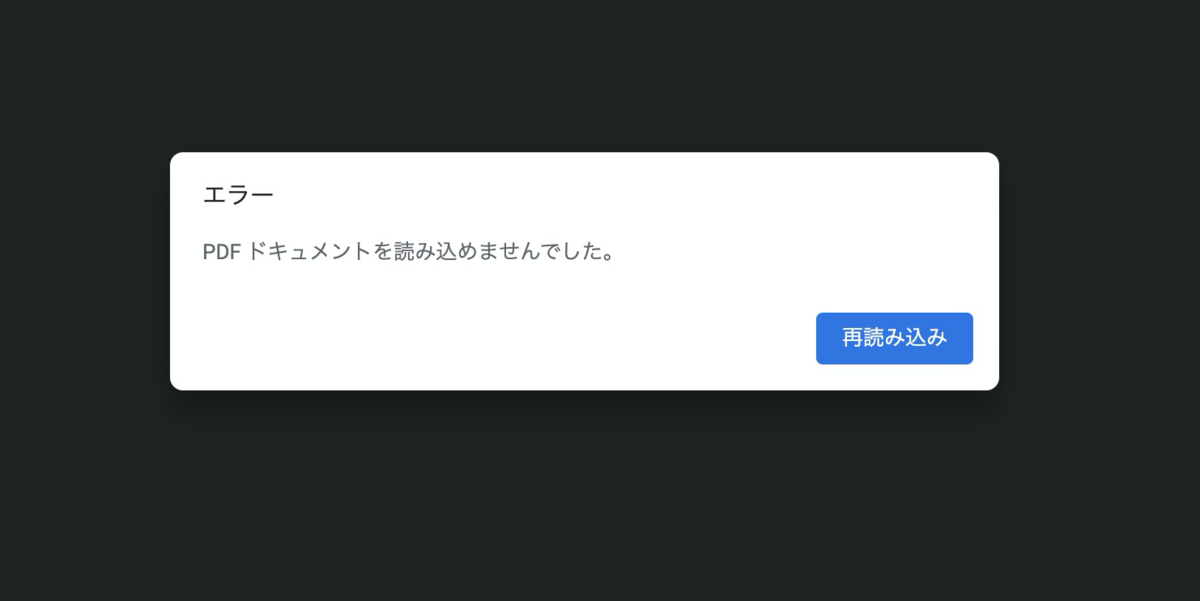
これはPDFがbase64に変換されたままの状態で、PDFとして読み込めないためにエラーとして出てきています。ブラウザで、API Gateway にアクセスするとここまでしかできないようです。なので、次に紹介する Cloud Front が必要になってきます。 - (参考)コマンドが使える方ならば、この時点でPDFダウンロードを試すことが出います。curl というコマンドを使えば、PDFを指定してファイルダウンロードができます。この時点で、PDFが正しくファイルとして取得できるかを試すことをオススメします。
curl -H "Accept: application/pdf" "APIエンドポイントURL" > test.pdf
"Accept: application/pdf" を指定してURLにアクセスするというのが必要なのですが、これがブラウザでURLを叩くだけでは指定ができないのです。ハマりポイント4ですが、筆者はいくら頑張ってもAPI Gateway だけではブラウザでPDFのダウンロードができませんでした。クライアント側で別プログラムを動かせばできそうですが、筆者の環境では、URLを叩くだけで実現する必要がありました。
API Gatewayの設定にあたっては、こちらやこちらの記事を参考にさせて頂きました。感謝します。
Cloud Front を使って設定を進めていきます。
Cloud Front の作成
Cloud Front をAWSで検索して、新たに作成を進めていきましょう。
Cloud Front の設定
- 「Create Distribution」→「Get Started」から新たに作成します。
- Origin Domain Nameは、API エンドポイントのURLをそのままコピペすれば良いです。『?key1=...』はいりません。すると、勝手にテキストが、Origin Domain Namと、Origin Path(スラッシュ区切り)に分かれて入力されるはずです。
以下、変更する箇所のみ記載します。 - Minimum Origin SSL Protocol は「TLSv1.2」。最新版を指定するため。
- Origin Protocol Policy は「HTTPS Only」。API Gateway はHTTPSのみのため。
-
Origin Custom Headers は、下記のように設定。
Accept application/pdf
Content-Type application/pdf
-
Cache and origin request settings は、「Use legacy cache settings」を選択して、「Whitelist」を選ぶ。「Accept-Encoding」「Accept-Language」をAdd しておきましょう。(ただ、たぶんここは何でも良いです)
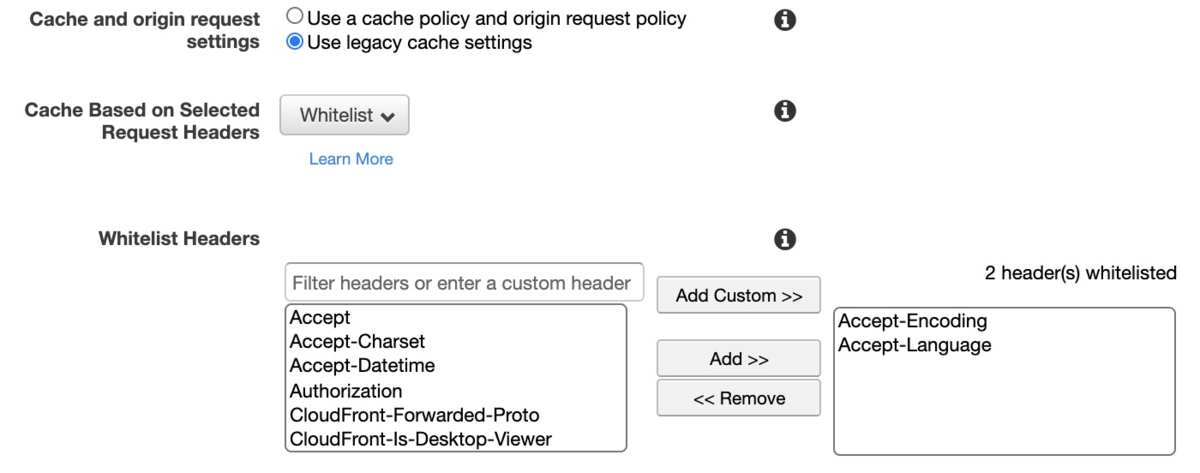
ここがハマりポイント5ですが、デフォルト設定や「Whitelist」の代わりに「All」などを選ぶとうまくいきません。
また、Accept を Add したくなるのですが、Origin Custom Headers で既にAccept application/pdf を入力している場合は、両方入れられないとエラーになります。
これらの点については、解決策も記事によってマチマチでした。こちらとこちらの記事を参考にさせていただきました。感謝します。 -
Forward Cookies は「All」、Query String Forwarding and Caching は、「Forword all, cache based on all」を設定。ただ、ここは状況に応じて変更してください。

-
Object Caching は、「Customize」にして、すべてのTTLを 0 にします。0にすることでキャッシュがなくなるとか、なんとか。

- 最後に右下の「Create Distribution」を押して完了です。
Cloud Front の URLへアクセス
- おそらくStatusが「In Progress」になっていると思います。3分ほど待てば、「Deployed」に変わるはずです。

これにより、Domain Name にhttps:// をつけてアクセスすると、OriginのURLに自動的にアクセスされるようになります。リダイレクトのような形ですね。そのときに、「Access:application/pdf」も付加した上でアクセスがされるようになるので、ブラウザでPDFが見れるようになります。 - Domain Name の URL に、『key1=aaa』をつけて、アクセスしてみてください。無事、目的のPDFが表示されたでしょうか。お疲れさまでした。
まとめ
今回はあんまり分析とは関係のないところで、システム的な記事を書きました。AWS Lambdaは便利な半面、いかんせん設定がどういう設定なのか、何のエラーなのかがわかりにくくて困りますね。
もしも、本記事がお役に立てましたら「はてなスター」をポチッと押す、読者になるボタンを押してもらえると励みになります。
参考書籍

![【POD】PHPでもサーバーレス!AWS Lambda Custom Runtime入門 (技術の泉シリーズ(NextPublishing)) [ 木村 俊彦 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/8068/9784844378068.jpg?_ex=128x128 "【POD】PHPでもサーバーレス!AWS Lambda Custom Runtime入門 (技術の泉シリーズ(NextPublishing)) [ 木村 俊彦 ]")
ご覧頂きありがとうございました。